
Claude is not a senior engineer (yet)
Claude is now incredibly good at assembling well-designed blocks – but it still falls apart when it has to create them.

Opus 4.5 is out and people cannot stop raving about it. AGI is nigh! It’s a step-change in capabilities!
Don’t get me wrong. It’s very impressive. But after trying it out in a real codebase for a few weeks, I think that view is overly simplistic. Claude is now incredibly good at assembling well-designed blocks – but it still falls apart when it has to create them.
To demonstrate, I’ll run through three real examples: a Sentry debugging loop where Claude ran on its own for 90 minutes and solved the problem; an AWS migration it one-shotted in three hours; and a React refactor where it proposed a hack that would have made our codebase worse.
The same pattern explains all three. And in doing so, it also demonstrates what senior engineers actually do – and why we’ll be safe from AGI for a long time.


The Good
Running a Playwright-and-Sentry debugging loop
The most impressive thing Claude Code has done for me is debug, on its own.
I was trying to attach Sentry to our system. Sentry is a wonderful service that creates nice traces of when parts of your code run. This makes it easy to figure out why it’s running slower than you expect.
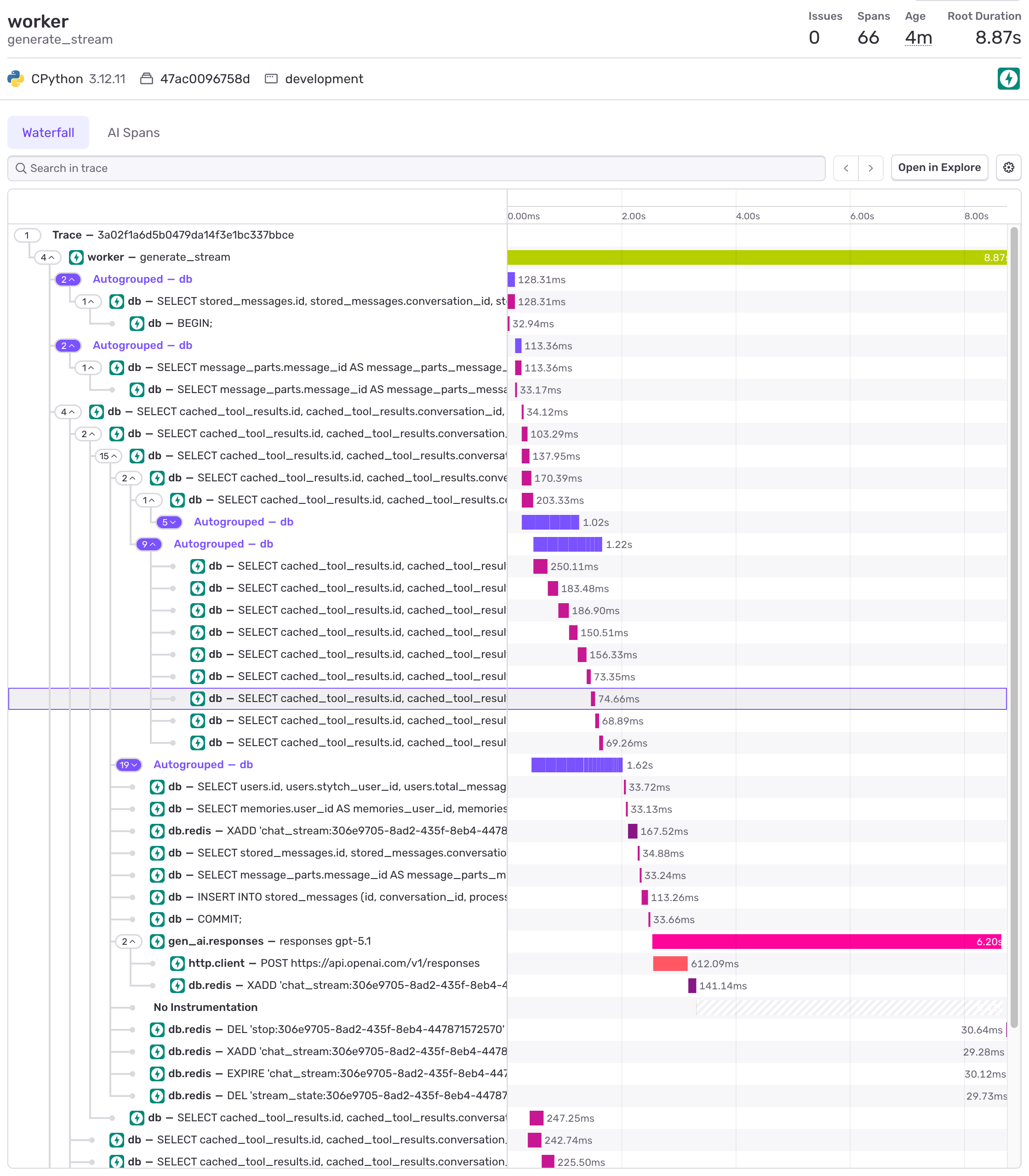
It’s usually very easy to set up, but on this day it wasn’t working. And there were no good debug logs, so the only way to figure out what was going on was to guess-and-check. I had to send a test message on our frontend, then look into the Sentry logs to see if we successfully set it up, then randomly try another approach based on the docs. It was frustrating and tedious.
So I had Claude write a little testing script with Playwright that logged into our website and sent a chat. Then I had it connect to Sentry by MCP, and look for the exact codepath I was trying to debug. Finally, I gave it the Sentry docs and told it to keep plugging away until it figured it out.
It took about an hour and a half, but Claude finally got it. This was pretty cool! The core loop of performance engineering is straightforward: make a code change, test, check tracing logs, repeat. With this tooling, Claude could do that work for us.
(The problem, if you’re interested, was that Sentry automatically sets up transactions for FastAPI endpoints but not for ones that return StreamingResponses. The solution was to write that in manually.)
Migrating from Modal to AWS ECS in an evening
I’ve used Modal happily for a year. It has the best UI for spinning up containers in the cloud on-demand. But last week we hit its limits, so I had to migrate us onto AWS.
I wanted to set up an autoscaling, containerized workflow on Amazon’s Elastic Container Service, since I knew this was the ‘right’ thing to do. I’ve set up plenty of Linux servers by hand, so I knew what to do. But I’ve never before touched Kubernetes or ECS. The pain of learning AWS’s terminology always put me off.
This time, I asked Claude to do it. I gave it Terraform and access to the aws command line tool. It one-shotted creating Dockerfiles for our code. Then it pushed them to AWS’s container registry, and set up the correct permissions using the cli, and set up the necessary AWS ECS configs in Terraform.
And it all worked on the first try! Amazing!
This is a straightforward task, but it would have taken me a day or two. I would have made a dozen mistakes and would have had to read through pages of AWS documentation. Claude crushed it, and got it all working in three hours late at night.
Conclusion
Both these use-cases are really impressive! They required a lot of detail and care. They each probably saved me a day and a half of low-value, tedious work. And Claude’s ability to track its own state and keep going was great! I can see why folks cannot shut up about Opus 4.5.
The Bad
What makes a good engineer?
I once knew a distinguished engineer named sweeks. Sweeks was legendary for his good code. People whispered about how he had single-handedly invented many of my employer’s paradigms for programming in OCaml.
Sweeks wasn’t a god. He wrote normal, bug-prone code, like you and me. He was good at coding because he was a gardener. Every time he walked into his codebase, he picked up his shears and manicured a bit of stray code. Over time, he rewrote every line of code over and over, tightening it down to only the perfectly-abstracted essentials.
Sweeks is an inspiration. So whenever I make a change in our codebase, I ask if it’s the most elegant solution. If not, I rewrite the code until it is. Putting in a hacky fix might take five minutes; repairing all the code around a change might take me thirty. But unless I’m in a rush, I always do the latter.
I bring this up because it’s a microcosm of what a senior engineer does. A senior engineer sees the non-obvious improvements and executes them quickly. A senior engineer identifies large step changes that are costly, but pay off in multiples down the road, and fights to get them through.
Opus is not a senior engineer.
Claude tries to write React, and fails
I was recently working on some gnarly React code. (In fact, it was gnarly because I vibe-coded it over Christmas and pushed it without properly cleaning it up.)
We had two components that both needed access to the same data: Component A had a ‘key’, and Component B had an ‘id’. And we had these data structures:
keyIdPairs: [(key, id)] // a list of tuples
idToData: Map<id, data>Our problem, at its core, was that Component A needed to look up data on-demand as well. What to do?
Claude, our idiot savant, proposed a linear lookup:
// Scan the list to find the matching id
id = keyIdPairs.find(pair => pair.key == key).id
data = idToData.get(id)But in context, this was obviously insane. key and id came from the same upstream source. So the correct solution was to derive a new map that updated whenever idToData did, keyToData: Map<key, data>.
If you give Claude the pure data problem, it comes up with the right solution. But in our actual codebase, it lost the plot. It couldn’t see the actual data problem amid all the badly-written React code. If I’d let it run wild, it would have made our frontend codebase worse.
Claude needs good legos
Nowadays, I think of Claude as a very smart child — one that loves to put together legos. Good infrastructure and abstractions are the lego blocks you give it. The bigger and better they are, the more you can do.
When I gave it Sentry, I could put it in a loop and watch it go. When I gave it Terraform and told it to go wild on the AWS CLI, it succeeded because Terraform is an excellent abstraction over cloud compute resources.
But when you don’t have good abstractions — like in our gnarly React code — Claude gets lost, and it can’t rescue itself.
Grant Slatton put it very well:




Since Claude can’t create the good abstractions. Claude’s powers are limited by how good the blocks you give it are. Have no illusions; Claude cannot reproduce Sentry and Terraform and Playwright. These are incredibly complex and well-designed pieces of code. And since Claude can’t create good abstractions on its own, there’s a limit to how much anyone can do with Claude alone. Even though everyone on X thinks you can vibe-code all software, I think the opposite is true: the value of good abstractions and well-designed infrastructure has never been higher.
If I had to boil down my criticism of Claude to one sentence, it’s this: Claude doesn’t have a soul. It doesn’t want anything. It certainly doesn’t yearn to create beautiful things. So it doesn’t produce good solutions. It doesn’t write elegant abstractions where there were none; it doesn’t manicure the code garden.
And this is all fine! It’s still a fantastic tool. But until it has a soul, we should all calm down a little. It’s nowhere near replacing all engineers. If anything, it makes us all much more important.
Great case study, loved the examples. As someone who used to spend hours/days on configuring dockerfiles and scripts for Kubernetes deployments, I realize how cool it is to one-shot it. But I also wonder, what unknown risks does this level of one-shotting introduce? Painstakingly tweaking each parameter to get the deployment to work would create some familiarity with each parameter. But if it's a fire-and-forget job, and you just move on, does it introduce the risk that the code has some vulnerabilities that you aren't aware of? Parameters that aren't tuned the way you'd like, which you didn't bother checking? (This could be just cope to feel like my attention was indispensable in deploying this code)
"If you give Claude the pure data problem, it comes up with the right solution. But in our actual codebase, it lost the plot. It couldn’t see the actual data problem amid all the badly-written React code."
Very interesting – so Claude wasn't able to spot that key and id came from the same upstream source and had a unique pairing? Is that what a senior developer would have spotted by scanning through the code? I'm surprised it would miss something that's such an easy win. So Claude just focuses on getting things to work, and not work in the best way possible, as Sweeks would, if I'm understanding it right. How Sweeks approached his code reminds me of how Hemingway approached his writing. Legend.
If you have insight into how Claude is cutting the concept graph now and forming these abstractions, do you think we have a handle on how to form higher-level abstraction blocks? i.e Is this a solvable problem that can be solved by just going down the road of whatever we're doing currently, or does it require a fundamentally different approach to get a "soul for Claude"?